Software code changes vs. ITIL’s change management
You say either and I say either,
You say neither and I say neither
Either, either / neither, neither
Let’s call the whole thing off.
–“Let’s Call the Whole Thing Off,” by George and Ira Gershwin
Developers need a place to track their code: to write new code and to move that code from development to test to production. They (hopefully) have software-specific tools for doing this–perhaps open source tools like git, Mercurial, subversion, or CVS, or closed-source tools like CA Software Change Manager (formerly known as Harvest). Developers will also have a defined process for “promoting” code–perhaps including policies on committing code, code reviews, and tools to assist with code migrating into production. Developers will often think of all this as “change management.”
People learning about ITIL, or more generally learning about IT service management (ITSM), learn about IT service change management. They learn about how IT service change management can be linked to other ITSM processes such as incident management or service continuity management. They learn about the value of communicating changes to the Service Desk, the need for change approvals commensurate with risk, the importance of having a change schedule, and how to build improvement through post-implementation reviews. ITIL people will often think of all this as “change management.”
When these two groups meet, and they each have their own idea of what change management is, you will often find arguments and people talking past one another. It takes a while (sometimes months or years!) to realize that two complementary processes are being discussed: software change management and IT service change management. Let’s talk about how they’re related.
Terminology
When I say RFC below, that means “Request For Change” and I am referring to one IT service change management change.
Why make a distinction?
You may ask, quite reasonably, why is this a useful distinction? Aren’t I talking about extra overhead? What’s the payback of calling out these two separate processes?
If you do not make a distinction, it’s likely you will not be able to get the benefits of IT service change management. If you do distinguish between software change management and IT service change management, here are some potential benefits:
- Developers are assured the changes they work on have significant business value
- Developers can reset expectations so that customers do not expect all requests will be implemented. Based on the scope of work, IT service change management can even escalate customizations or big units of work to IT governance groups.
- Service Desk and others can see a change calendar with a list of ALL changes that will occur over the next week/month/quarter
- Service Desk and others can better investigate outages: most outages are due to changes; having a list of changes that have occurred is very helpful for the Service Desk
- Users can see changes in your service management portal/front-end
- Campus departments can receive reports on the changes they requested/changes that affected them using language they understand
- IT better understands the potential risk of changes based on the affected services/components. For example a software code change may affect a network load balancer’s ability to function
Software changes are one type of IT service change

IT services can be changed in many ways: service policies or procedures might be updated, new servers could be installed, disk space might be reclaimed, network switches might be reconfigured, or the software delivering services might be changed. All of these things can be tracked as RFCs.
From this perspective, software change management is a “sub-process” that is used to handle any RFC requiring software changes. Conceptually, one RFC could include software changes, network changes, and also other changes.
5,000 foot view vs. ground-level view
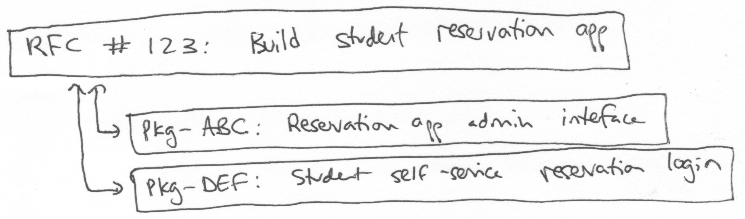
RFCs will talk more about business impact and will be less specific than software code changes. RFCs are the 5,000 foot view of what’s going on. Software code changes are the ground-level view. The software change records, describing exactly what’s changing, can be related to the higher-level RFCs.
For example, if changing how GPA is calculated:
RFC: “Change GPA calculation so A+ counts as 4.00 rather than 4.33”
Software code change: “if grade>4 then gpa_grade=4 else gpa_grade=grade”
Sample data collected in RFCs vs. software code changes
As another way of comparing the two processes, let’s look at the sample data collected for RFCs vs. for software code changes. By thinking about the data collected you can better understand the types of decisions made for each process.
RFC
Sample data collected:
- Business approvals
- Cost estimates
- Risk to the service
- Anticipated go-live date
- How well was the change deployed?
Decisions that can be made: is this change worth the cost? is this change worth the risk? how risky is this change based on our track record? are there any potential collisions with other changes affecting this service? how might this change affect our service levels?
Software changes
Sample data collected:
- Detailed requirements and/or tests
- Files changed
- What changed in each file
- Code commits (e.g. file “register.php” was changed 5 times and the functionality added each time–can be used to blame/praise later)
Decisions that can be made: does this code function as specified? does this code meet style guidelines and can it be understood later? are all the modifications needed to satisfy the requirements? are any security issues introduced by this code? is there test coverage for all code?
How to link the two processes
The high-level idea/request can be coded as an RFC. The RFC can then be classified and approved per your IT service change management procedure.
After the RFC has been approved, software code changes are recorded and linked to the RFC. The bulk of the work then occurs in the software change management system.
Ideally, the system recording RFCs can be integrated with the software change system–for example to promote code automatically as an RFC progresses. RFCs can be updated as code is developed, for example through the software tool adding comments to the RFC as commits are made.
At a minimum, there should be a manual linkage between the two–even if it’s putting the RFC into the software change’s name/identification. When an application administrator goes to install RFC 123 into production, they should be able to see the code changes that correspond to that RFC.
Where’s the backlog?
In this model, there are two big places for potential backlog: RFCs that have not yet been approved, and approved RFCs that have not been developed.
In my mind it’s best not to approve the RFCs if you don’t reasonably think you can address them in the next month. This minimizes the work-in-progress for software change management. It also better sets expectations for users and others who look at RFC status to get a rough idea of what’s going on with their requests.
However, if you have a lot of approved RFCs then a second backlog will appear within software change management: the approved RFCs that have not begun in development.
Ideally, the two processes learn from one another so developers get a heads up about potential RFCs, and RFCs are only approved if developers have the bandwidth/capacity for them.